倒卖数据可真行——记一次数据溯源
声明 本文中涉及的所有隐私数据均彻底删除,本文目的是 揭露某些倒卖数据的人 ,记录数据溯源过程。敬告各位网友请勿尝试。
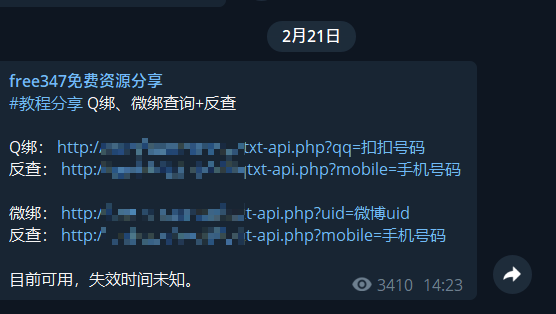
起因 前两天在tg上看到了一个查询Q绑的接口。我心想,这不是去年就泄露的数据吗,怎么到了今天还有人在弄。
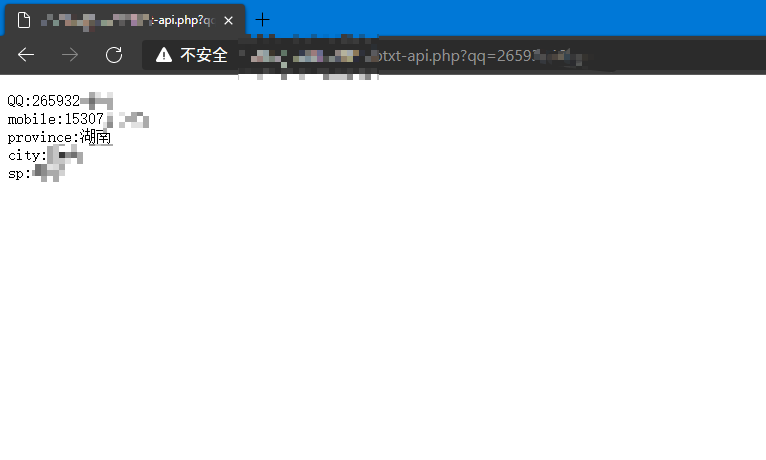
进一步探索 然后我就很好奇的查询了一下,发现数据确实是正确的,就是去年十一月份泄露的那个。
然后我就访问了下他的主页……
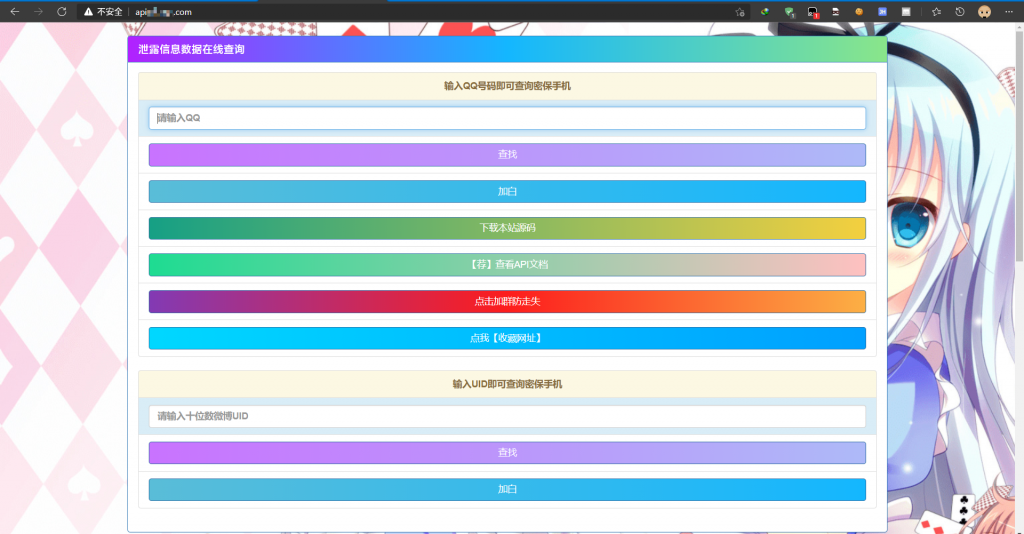
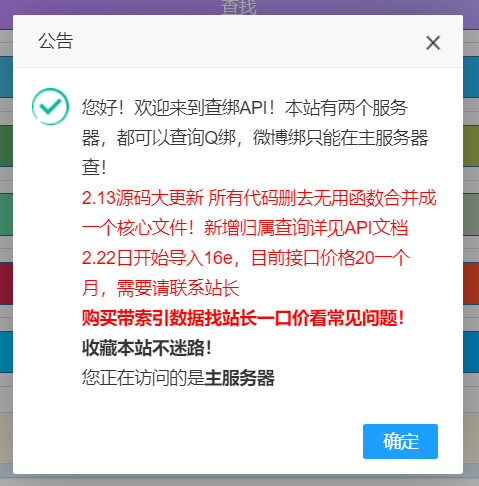
发现这个页面真的辣眼睛,这用的是多少年前的模板,感觉就是哪个代刷网改过来的,各种弹窗乱窜……
就是一个字:丑 !(这种十分违和的界面就像是小学生做出来的一样)
然后他还提到卖数据,其实之前是没有看到这个公告的,应该是2.26才加上的。
先不说卖接口这个迷幻的操作,你这卖的数据库也太贵了吧
你这带个索引就坐地起价了??
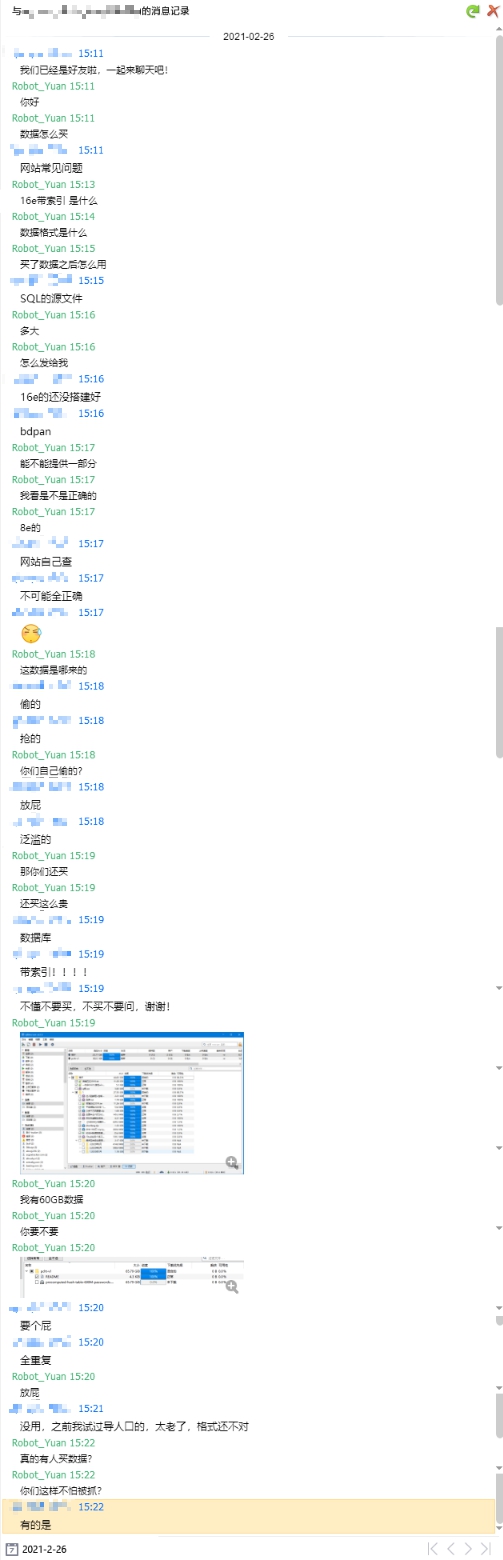
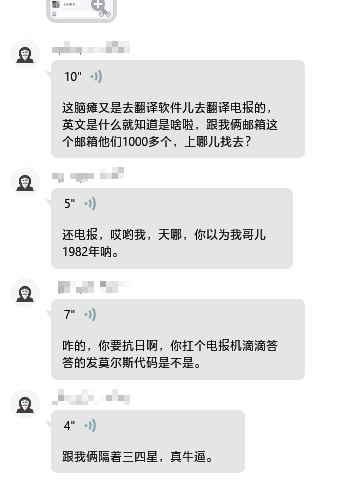
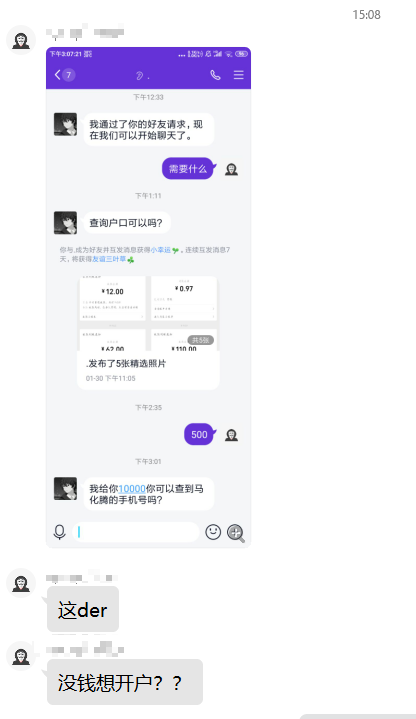
和客服联系 于是我决定会一会他们的客户,请看下面的聊天记录,单击可以放大。
以上都是我和客服的聊天记录。
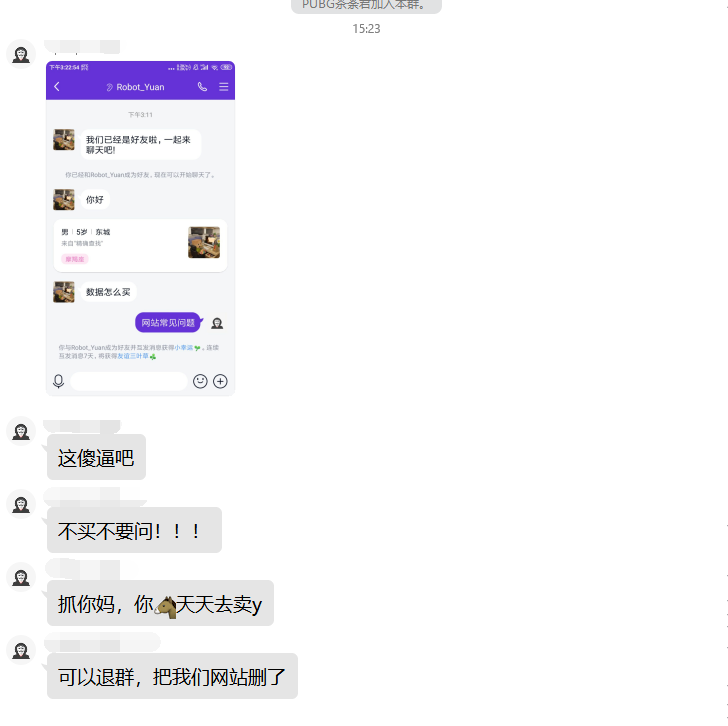
再po几个其他人的聊天记录
电报:Telegram(非正式简称TG)是跨平台的即时通信软件,用户可以相互交换加密与自毁消息,发送照片、视频等所有类型文件。
来自Telegram - 维基百科,自由的百科全书
补充一下什么是电报。因为电报不被审查,所以有很多黑色交易 发生在这里。
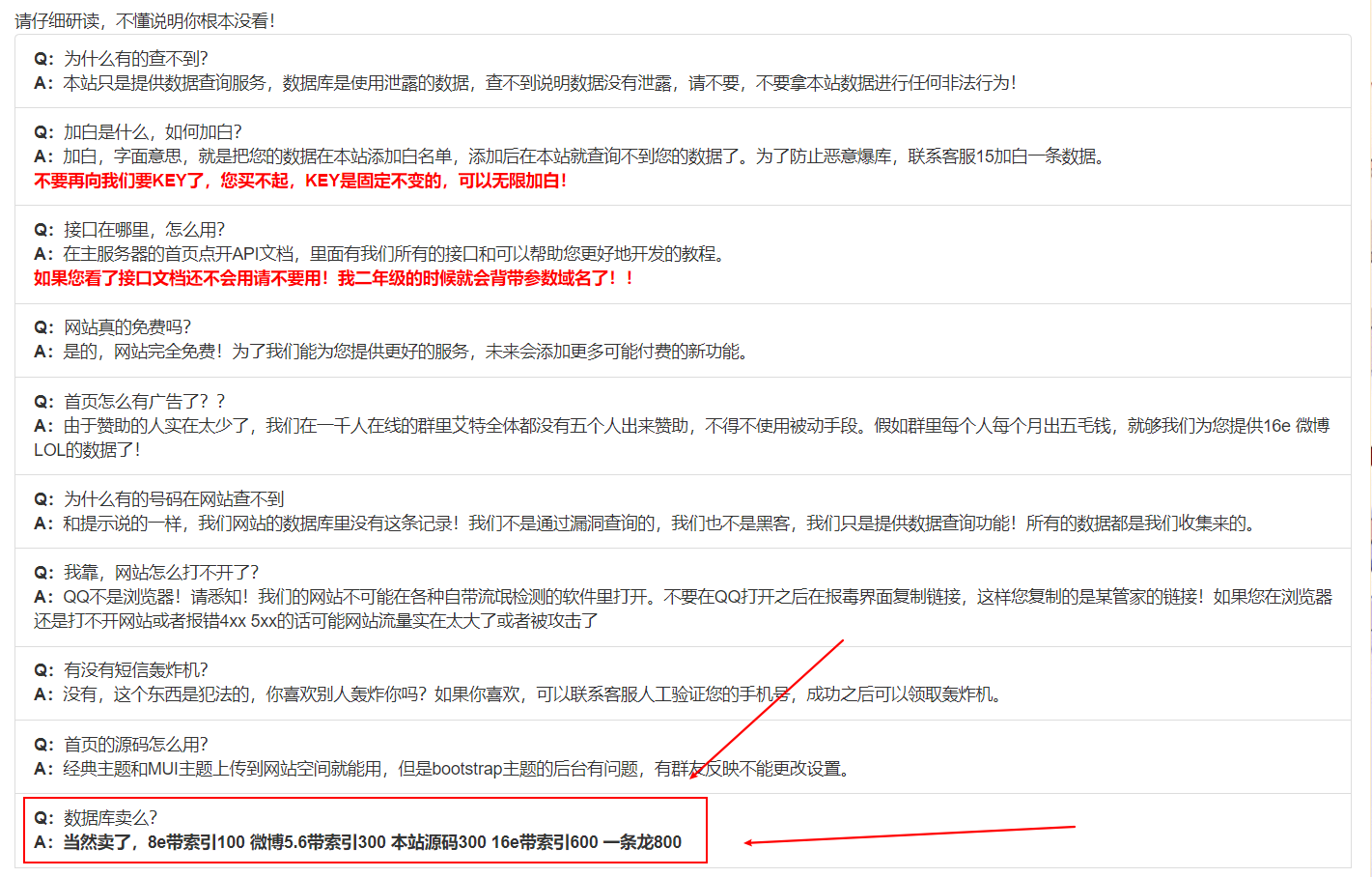
运营模式 总结一下他们的盈利方式
首页广告收入(文字66元/月 横幅100元/月 置顶+20元)
加入白名单收入(15元/次)
卖数据(8e带索引100 微博5.6带索引300 本站源码300 16e带索引600 一条龙800)
支出就服务器费用,连数据库都可以在网上找到
寻找数据 我就很好奇他们的数据是哪里来的,这个网页做的这么烂,说明他的技术很不行呀。于是就更坚定了我找到数据的决心。
先在百度上搜索,结果发现没有什么有用信息,要么就是回到原站,要么就是其他软件调用了这个网站的接口,还有的就是一些新闻。
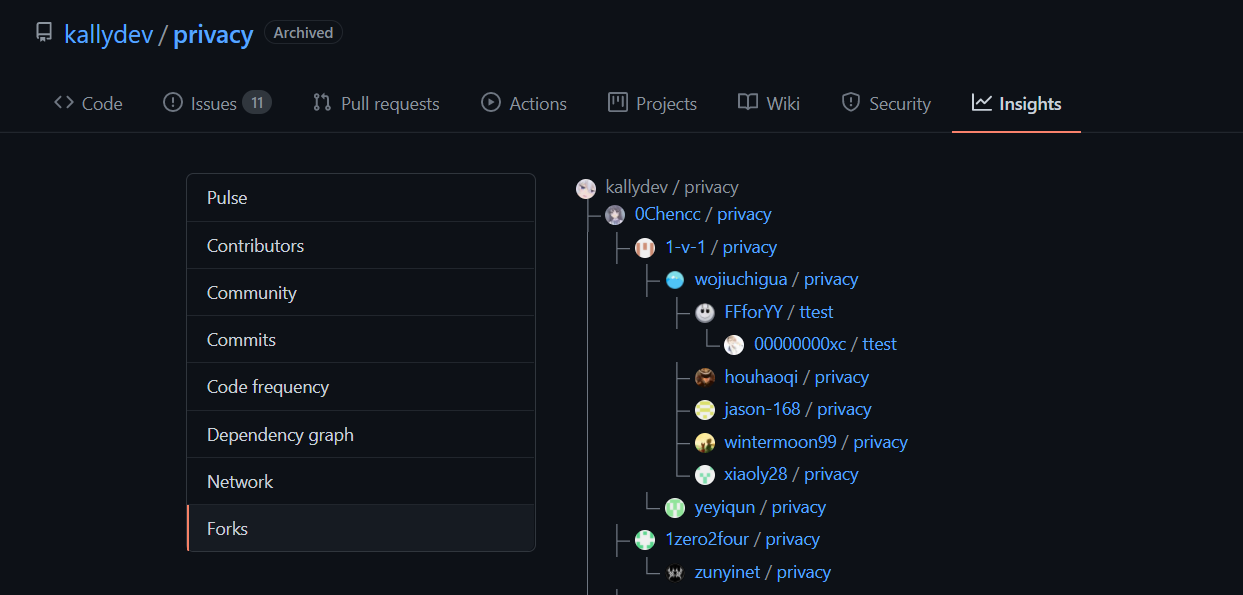
随后我转向了Github,发现了一个收到律师函的项目。
尽管这个仓库已经被清空了,但是——
怎么可能会消失呢,随便找个fork就可以看见了
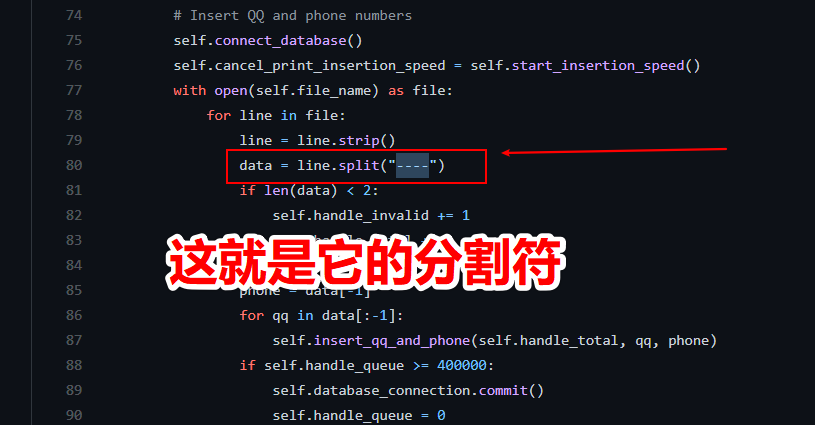
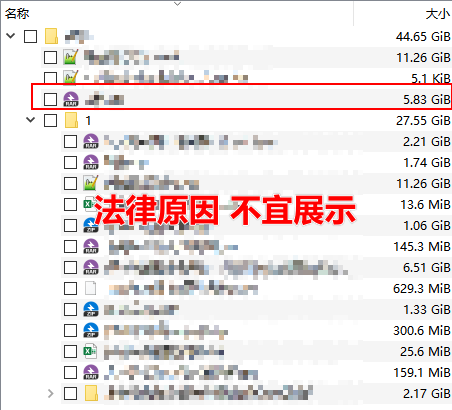
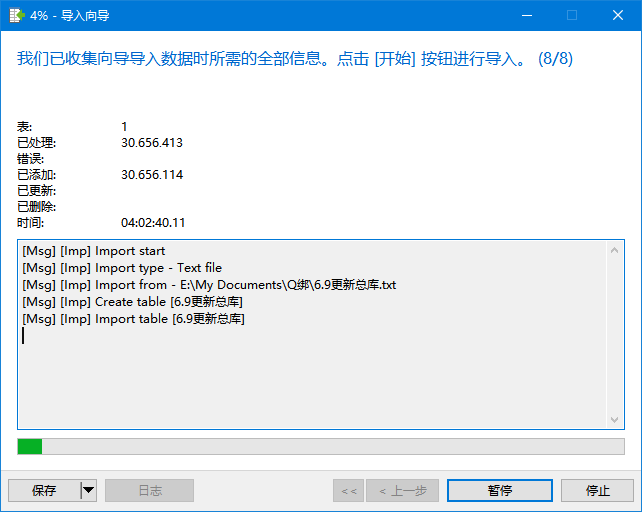
然后就找到了这个库的名字 6.9更新总库.txt ,和它的存储格式 QQ号—-手机号 ,接下来就好搞了
上谷歌去搜了一下,排除了一些无效和收费的网站后,果然就找到了。
总不可能真的上暗网吧,然后通过一些操作,就找到了一串神秘字符串
丢到下载软件里一看
艹!!!
还这么多
下了三个多小时后,终于下完了
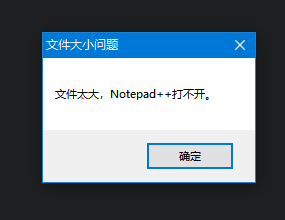
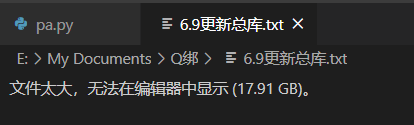
打开数据 结果一个意想不到的事情发生了,这个文件太大了,打不开。
那还能这么办呢?
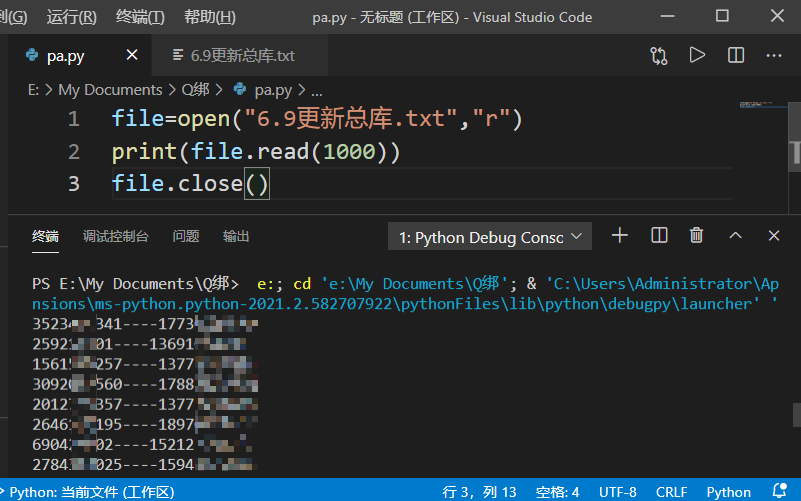
直接三行python代码解决,预览一下文件内容是什么
1 2 3 file=open("6.9更新总库.txt","r") print(file.read(1000)) file.close()
查询肯定不能这样子搞,得搞个数据库
就是这个导入速度太**慢了,四个小时才导入三千万条
可能python配上多线程会快一些,这里就不赘述了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 # From http://blog1.wktadmin.com:11112/?p=1900 import datetime from collections import defaultdict import pymysql import os def _build_sql(insert_dict): sql_list = list() for table_name, insert_list in insert_dict.items(): if not insert_list: continue sql = f'INSERT INTO {table_name} (qq_number, mobile ) VALUES ' len_insert_values = len(insert_list) count = 0 for qq, mobile in insert_list: sql += f"('{qq}', '{mobile}')" count += 1 if count != len_insert_values: sql += ',' else: sql += ';' sql_list.append(sql) return sql_list def to_mysql(filename): connection = pymysql.connect(host='192.168.10.224', user='root', password='root', database='ku', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor) with connection: all_count = 0 # start_time = datetime.datetime.now() insert_dict = { 'qq_0': [], 'qq_1': [], 'qq_2': [], 'qq_3': [], 'qq_4': [], } len_qq_all = 0 with connection.cursor() as cursor: with open(filename) as f: for line in f: try: *qqs, mobile = line.strip().split('----') except Exception: print('error', line) continue for qq in qqs: if len(mobile) > 64 or len(qq) > 64: continue table_name = 'qq_{}'.format(int(qq[-1]) % 5) insert_dict[table_name].append((qq, mobile)) if len_qq_all >= 10000: all_count += 10000 for sql in _build_sql(insert_dict): try: cursor.execute(sql) connection.commit() print('-flle_name: {}----------, time: {} seconds, sql: {}'.format(filename, ( datetime.datetime.now() - start).total_seconds(), sql[:18])) except Exception: import traceback print(traceback.format_exc()) connection.rollback() continue insert_dict = defaultdict(list) len_qq_all = 0 else: len_qq_all += 1 # 最后执行一次 for sql in _build_sql(insert_dict): try: cursor.execute(sql) connection.commit() print('-flle_name: {}----------, time: {} seconds'.format(filename, ( datetime.datetime.now() - start).total_seconds())) except Exception: import traceback print(traceback.format_exc()) connection.rollback() continue # if __name__ == '__main__': from concurrent.futures import ThreadPoolExecutor, as_completed files = [os.path.join('out', x) for x in os.listdir('./out')] print(files) start = datetime.datetime.now() pool = ThreadPoolExecutor(9) futures = [] for file in files: futures.append(pool.submit(to_mysql, file)) for x in as_completed(futures): print(x.result())
结语
不义而富且贵,于我如浮云
——《述而》
倒不如做些更有意思和意义的东西_(好像没啥)_
还别说,这次追溯的经历还是学到了一些东西,顺便回顾了一下回形针以前的一期视频。
拿别人的 隐私信息 谋取利益本来就是 不道德 而且 违法 的事,抛开tg上的机器人不说(因为管不到),这种在国内公开查询而且还售卖的行为就十分令人愤怒,尽管QQ屏蔽了这个网站,但却不能根除它。也许,需要有量的大佬来D?还是要GFW帮忙?
感觉很多事情本末倒置了,用心做分享的网站被几百G流量攻击,这种以隐私来牟利的网站却春风吹不尽 。
难道,真像DIYgod大佬说的那样吗?
这个世界就是这样,改变不了的,算了吧
我与这个世界的最后一次抗争 DIYgod
藏个彩蛋,就在这个页面里,想办法找到吧
console.log(“彩蛋:富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善”)